HDFS 的 Shell 操作
基本格式
hadoop fs ...,或 hdfs dfs ...。
后面的命令用法和Linux命令操作用法基本差不多。
常用命令
| 命令 | 作用 | 示例 | 说明 |
|---|---|---|---|
hadoop fs -mkdir 文件名 |
创建文件夹 | hadoop fs -mkdir /xiyou/bajie |
创建/xiyou/bajie的文件夹 |
hadoop fs -moveFromLocal |
剪切本地文件上传倒hdfs流经 | hadoop fs -moveFromLocal a.txt /xiyou |
将本地的a.txt剪切掉,上传到/xiyou目录下 |
hadoop fs -copyFromLocal |
拷贝本地文件上传倒hdfs流经 | hadoop fs -copyFromLocal b.txt /xiyou |
将本地的b.txt上传到/xiyou目录下,本地文件还在 |
hadoop fs -put |
同-copyFromLocal |
hadoop fs -put wukong.txt /xiyou |
将本地的wukong.txt上传到/xiyou目录下,本地文件还在 |
hadoop fs -appendToFile |
追加一个文件到已经存在的文件末尾 | hadoop fs -appendToFile jingubnag.txt /xiyou/wukong.txt |
将jingubang.txt里的内容追加到wukong.txt末尾 |
hadoop fs -copyToLocal |
从HDFS拷贝到本地 | hadoop fs -copyToLocal /xiyou/a.txt ./ |
把a.txt下载到本地 |
hadoop fs -get |
同-CopyToLocal |
略 | 略 |
其他命令
- -ls: 显示目录信息
- -cat:显示文件内容
- -chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
- -cp:从HDFS的一个路径拷贝到HDFS的另一个路径
- -mv:在HDFS目录中移动文件
- -tail:显示一个文件的末尾1kb的数据、
- -rm:删除文件或文件夹
- -rm -r:递归删除目录及目录里面内容
- -du统计文件夹的大小信息
- -setrep:设置HDFS中文件的副本数量
HDFS 的 API 操作
Maven 和 idea 的安装与配置
- 下载maven,防灾一个没有中文没有空格的路径下;
- 配置maven环境变量;
- 修改本地仓库路径和镜像(要进入setting.xml去修改!!);
- 安装idea,并修改maven配置,在
File-New Projects Setup-Settings for New Projects...里进行全局修改。
客户端代码操作常用套路
- 获取客户端对象
- 执行操作命令
- 关闭资源
以创建文件夹为例
- 先创建一个maven项目;
- 添加相关依赖坐标:
org.apache.hadoop hadoop-client 3.1.3 junit junit 4.12 org.slf4j slf4j-log4j12 1.7.30 - 日志添加。在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n - 在
/src/man/java下创建一个 com.shengrihui.hdfs 包; - 创建 HDFSC列宁他 文件
1 | package com.shengrihui.hdfs; |
close(),init()是为了封装代码。
运行后结果: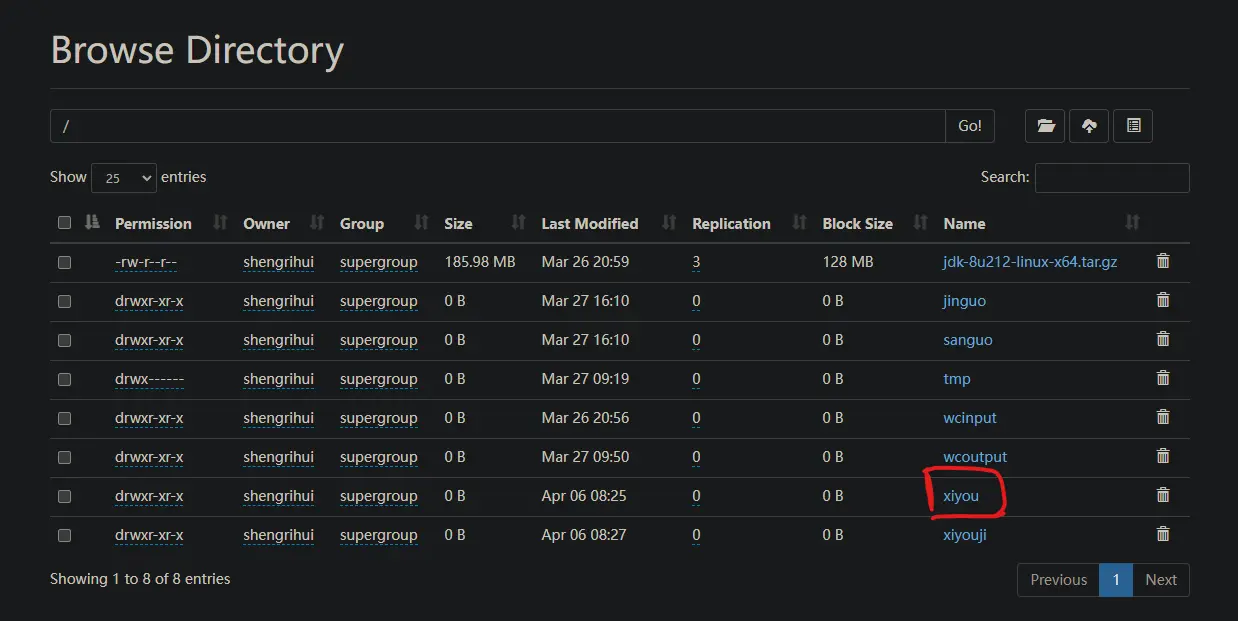
上传
1 |
|
运行结果: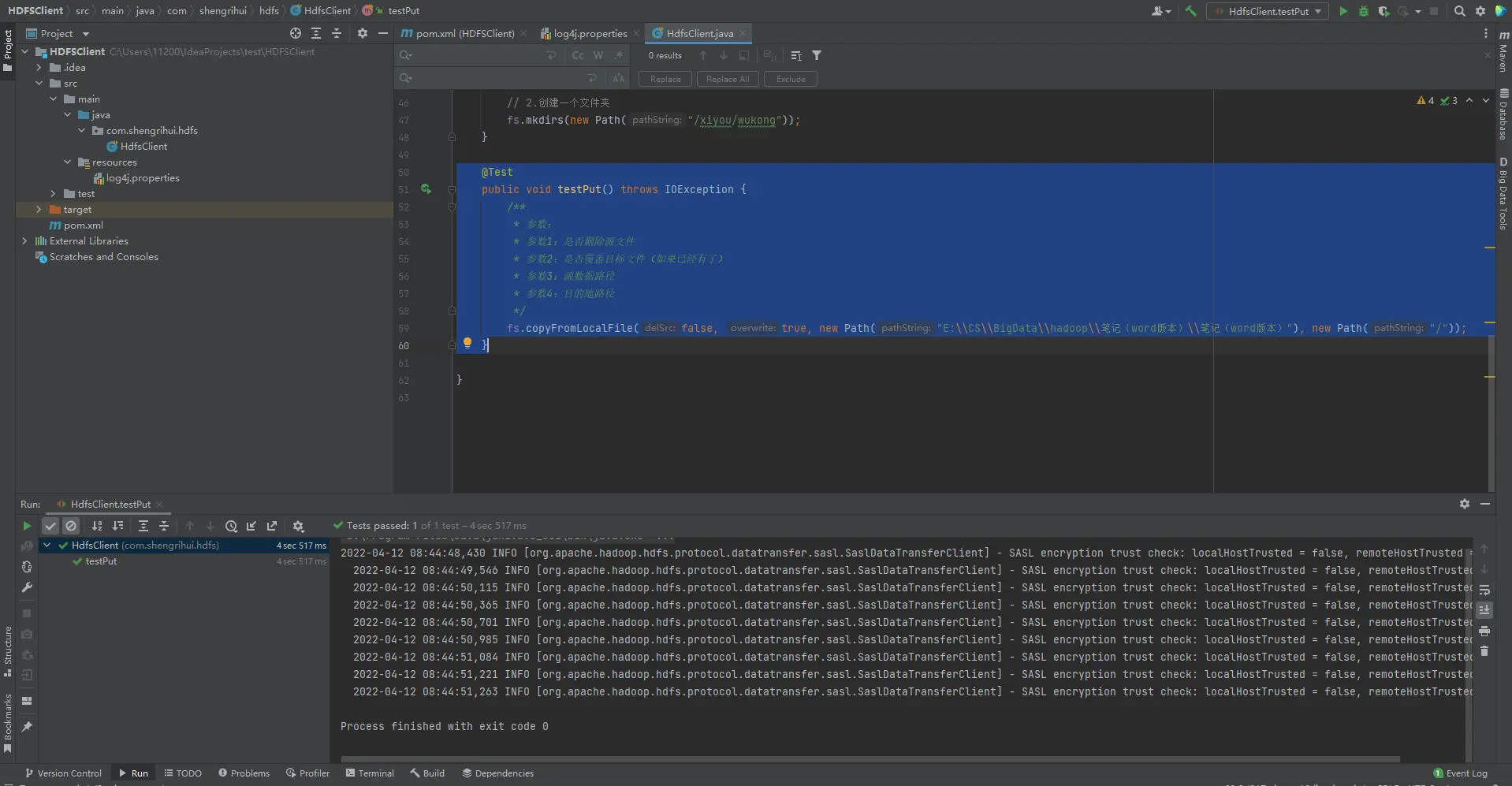
参数优先级
参数优先级排序:
(1)客户端代码中设置的值 >
在init里configuration.set("dfs.replication","3");
(2)ClassPath下的用户自定义配置文件 >
在resource目录下新建文件hdfs-site.xml,写入内容;1
2
3
4
5
6
7
8
9<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(3)然后是服务器的自义配置(xxx-site.xml) >
(4)服务器的默认配置(xxx-default.xml)
文件下载
1 | //文件下载 |
运行结果:略
删除
1 | //删除 |
运行结果:略
文件的更名和移动
1 | //文件的更名和移动 |
获取文件详细信息
1 | // 获取文件详细信息 |
运行结果: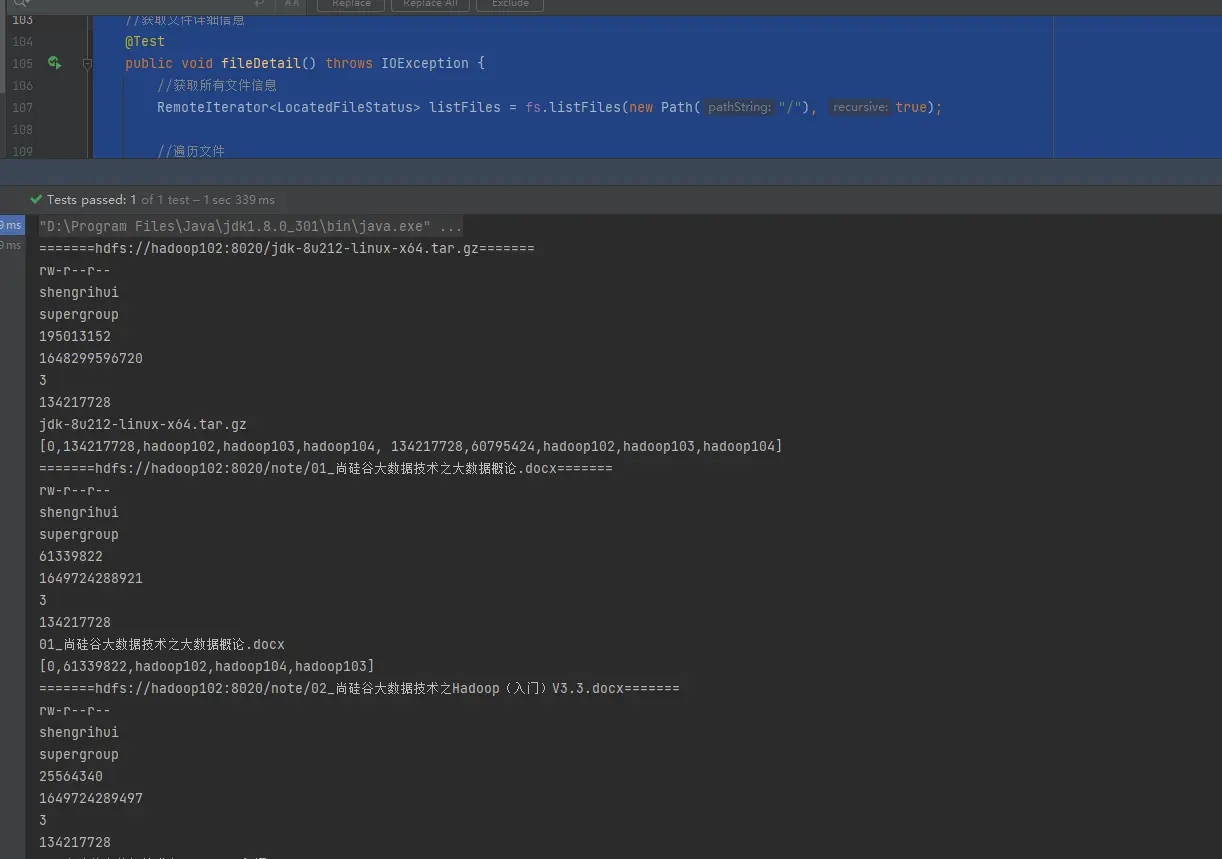
其中,大文件会按快大小128M分成好几个块;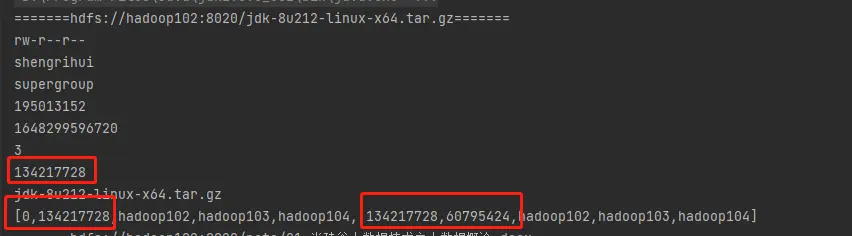
判断是文件夹还是文件
1 | // 判断是文件夹还是文件 |
HDFS读写流程
HDFS 写流程

(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
还有是否有权限上传
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
节点的选择涉及到节点距离最近、负载均衡(如果多个客户端都在写,那就pass这个节点)
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
为什么不是多个节点同时连接客户端?防止因为有任何一个节点没有完成而一直在等;
到dn1的时候同时就往后倒dn2;
最小单位是516字节(4个校验位),攒倒64kB的packet发送;
ACK队列,接受下一端是否接受成功,用于备份。
网络拓扑-节点距离计算
节点距离:两个节点到达最近的共同祖先的距离总和。
机架感知(副本存储节点选择)
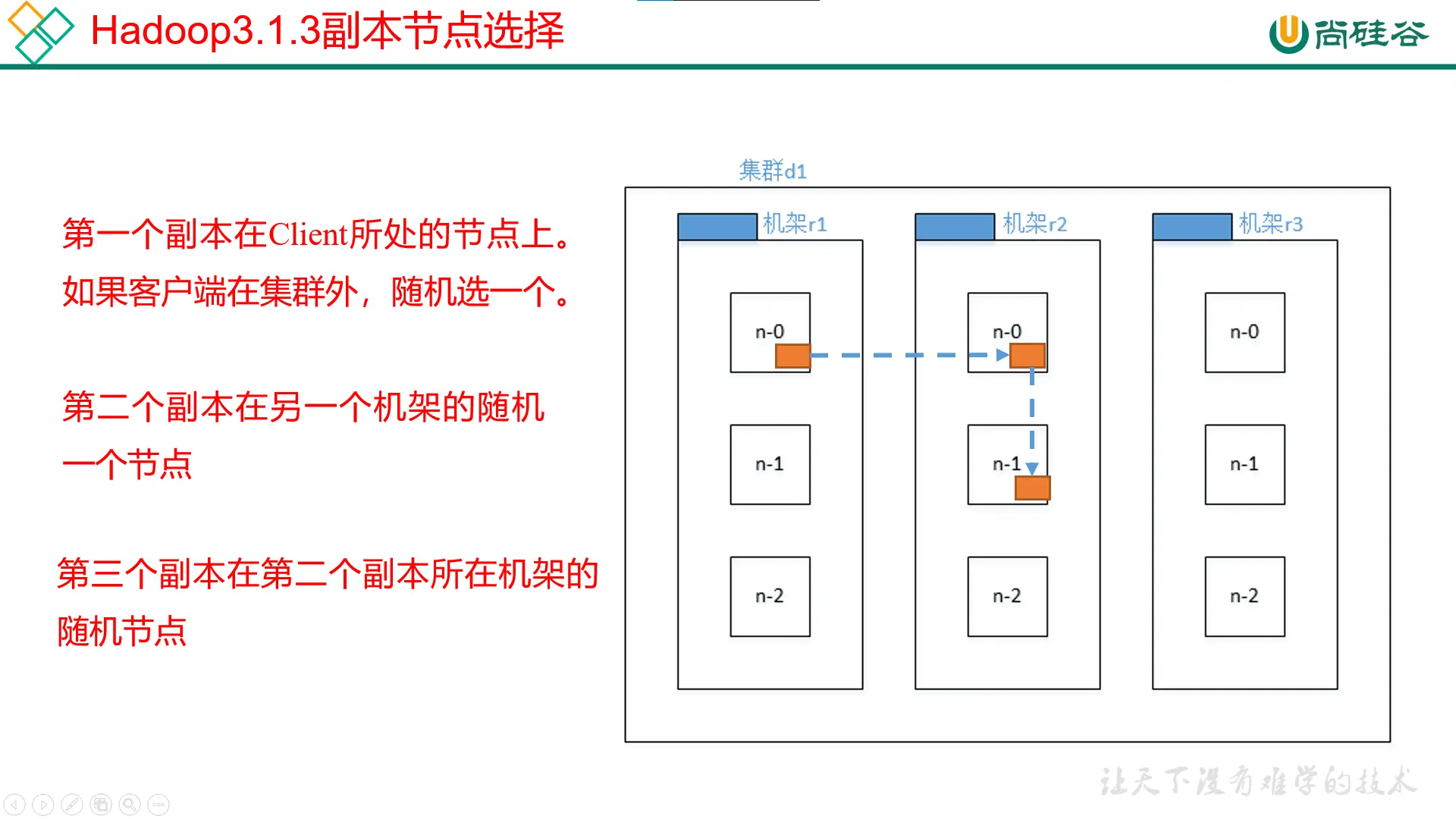
第一个副本:本地(如果客户端不在集群,随机算一个)
本地是为了上传的速度
第二个副本:另一个机架里随机
另一个机架是为了数据的可靠性
第三个副本:和第二个同一个机架随机
兼顾可靠性和速度
HDFS读数据流程
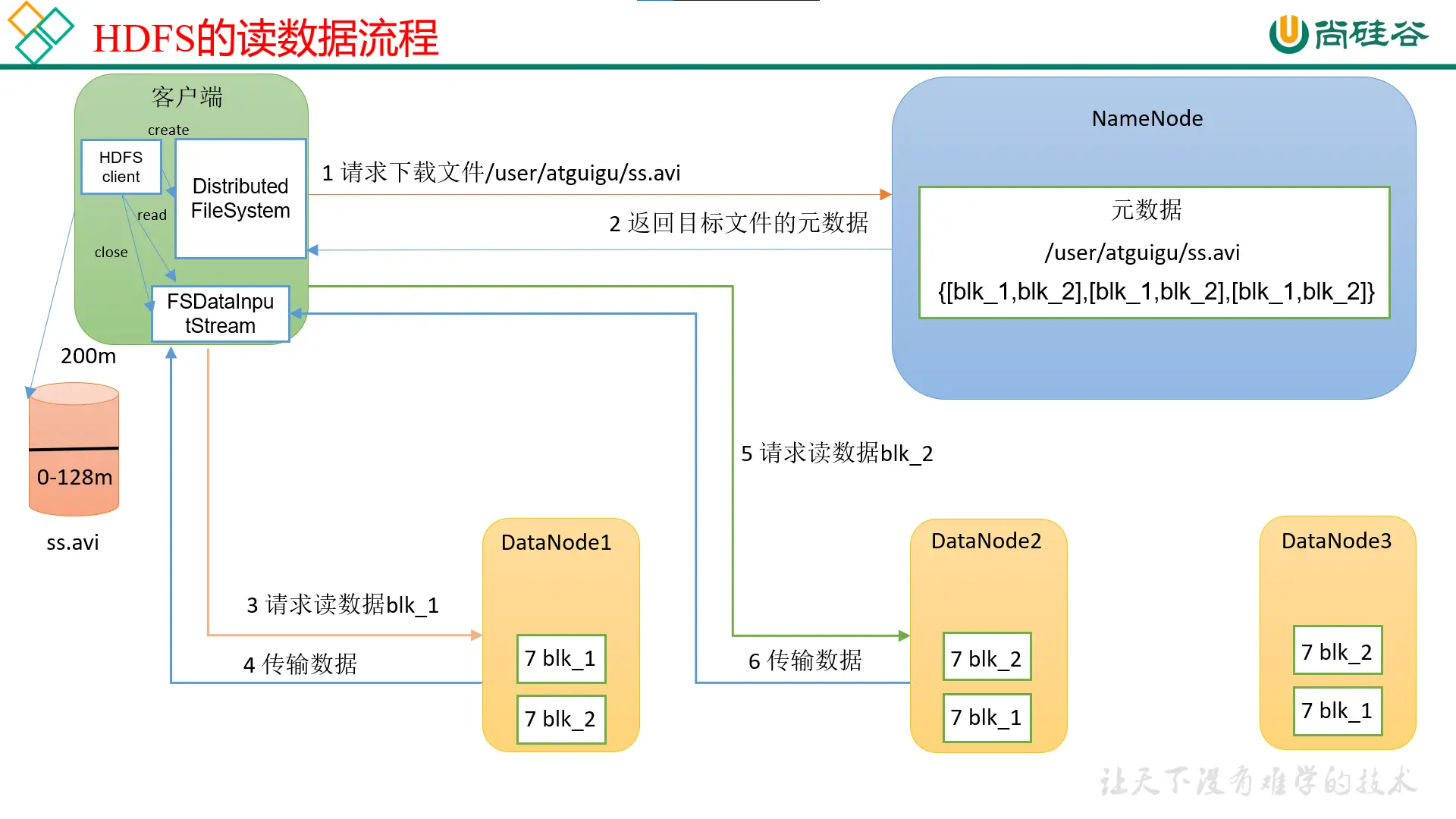
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
节点距离最近,也考虑负载
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
串行读,先读第一块,再读第二块
其他(了解和理解)
- NameNode和SecondaryNameNode
- NN和2NN工作机制
- Fsimage和Edits解析
- CheckPoint时间设置
- DataNode
- DataNode工作机制
- 数据完整性
- 掉线时限参数设置

