很少截图,因为懒。
hello world
1 |
|
编译:g++ -o2 -std=c++14 -fopenmp hellp_world.cpp -o hello_world-02 哦二不是零二:
-O0
-O1
-O2
-O3
编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
运行:
- `./hello_world’
OPM_NUM_THREADS=2 ./hellp_world设置环境变量,控制可以使用的线程数。
结果: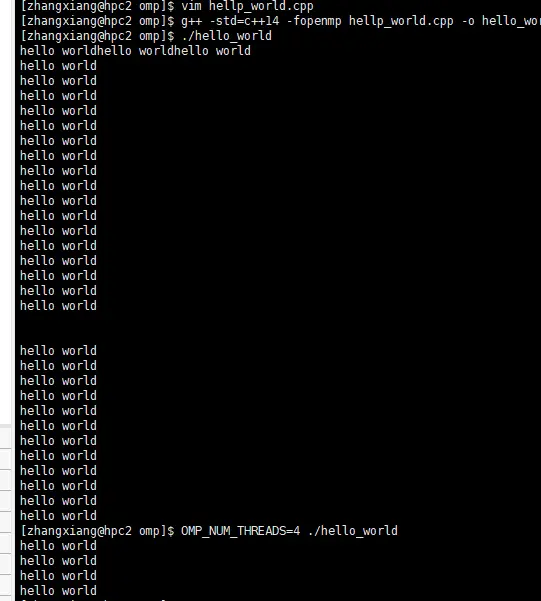
库函数
需要#include <omp.h>
#pragma omp parallel num_threads(4)设置生成的线程数量,这个应该不算库函数。
| 函数 |功能和作用 | 示例 |
| ——- | ——- | —— |
|omp_get_thread_num() | 获得当前这个线程的编号id | int i = omp_get_thread_num(); |
|omp_get_num_threads() | 获得当前线程总数 | int n = omp_get_num_threads();|
| omp_set_num_threads(); | 在串行部分设置线程个数,优先级比环境变量高 |omp_set_num_threads(6); |
|omp_get_max_threads() | 这是什么东西?? | .. |
线程数设置的优先级:指导语句的num_threads(),库函数omp_set_num_threads();环境变量;编译器默认。
parallel for
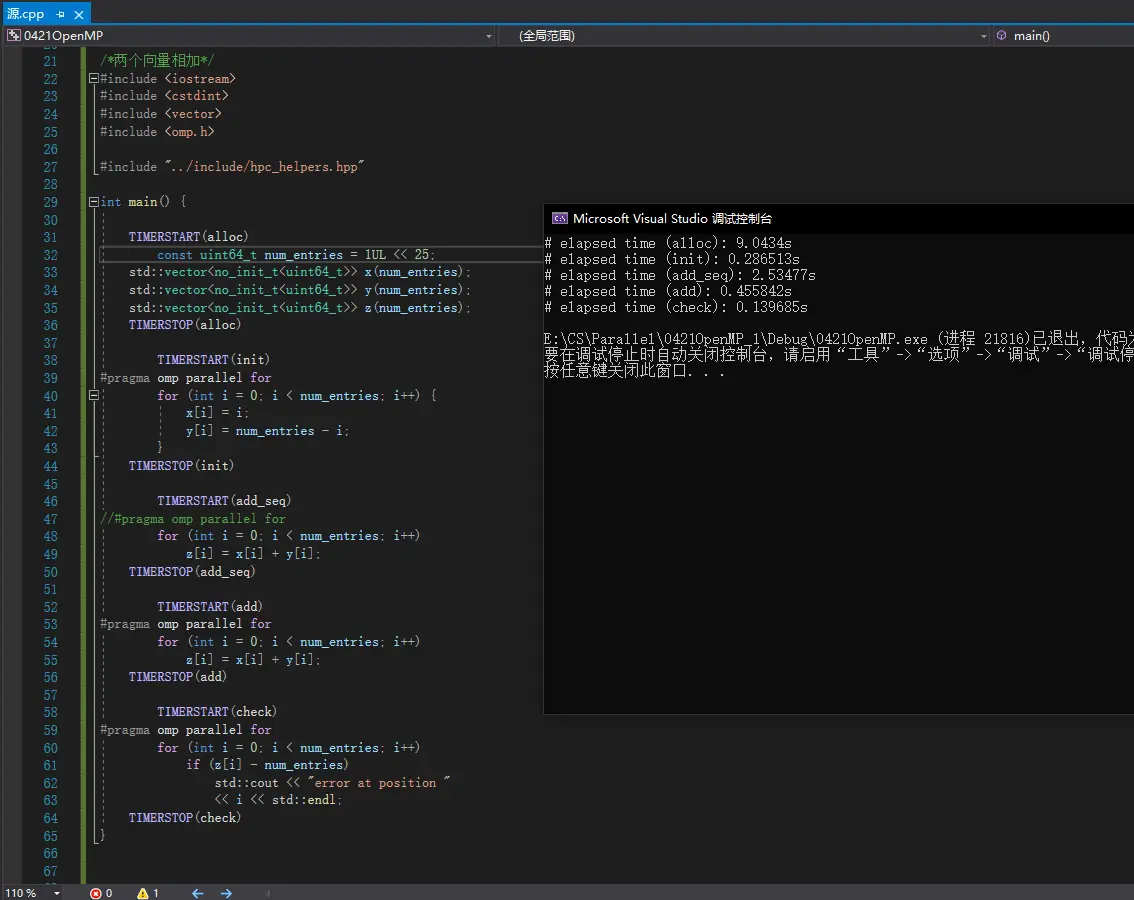
隐含同步
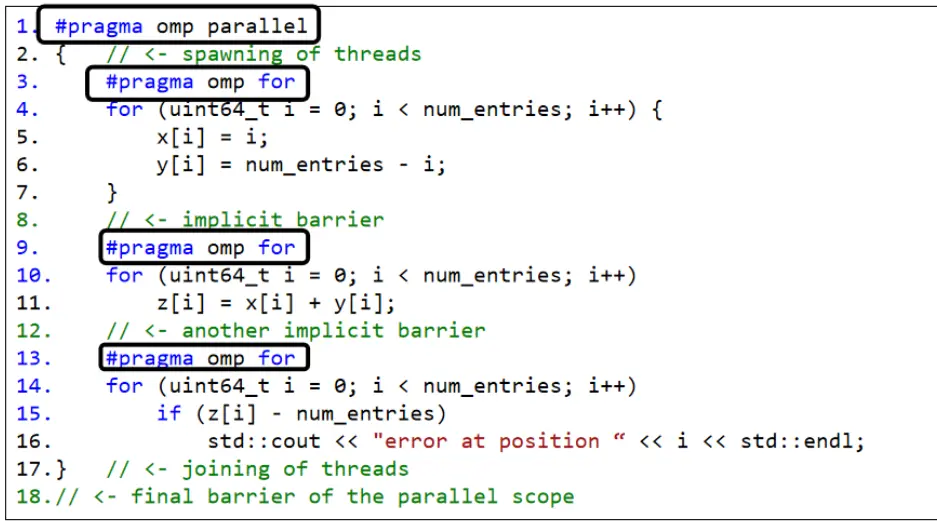
将#pragra omp parallel for写成1
2
3
4
5
{
#
...
}
前后数据、工作有关系的情况下。比如锁,数据的运算一定是在初始化之后,那之前参与初始化的线程肯定要同时结束才行。
在一些不需要隐含同步的地方,可以用nowait,即#pragma omp for nowait。
变量共享和私有化
private
1 | /*变量共享和私有化*/ |
输出: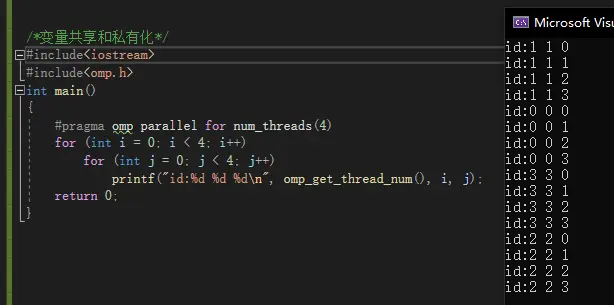
将i和j放在外面1
2
3
4
5
6
7
8
9
10
11
12
int main()
{
int i = 0;
int j = 0;
for ( i = 0; i < 4; i++)
for ( j = 0; j < 4; j++)
printf("id:%d %d %d\n", omp_get_thread_num(), i, j);
return 0;
}
结果: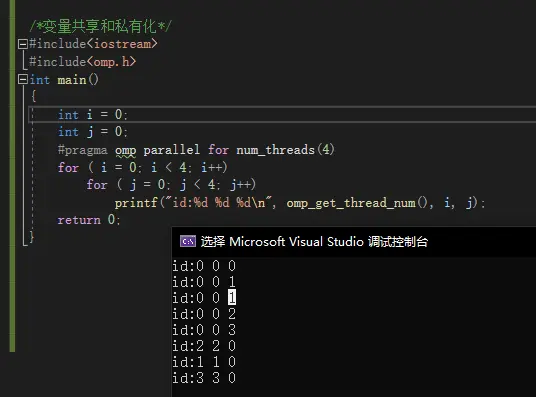
加入private1
2
3
4
5
6
7
8
9
10
11
12
int main()
{
int i = 0;
int j = 0;
for ( i = 0; i < 4; i++)
for ( j = 0; j < 4; j++)
printf("id:%d %d %d\n", omp_get_thread_num(), i, j);
return 0;
}
之前在循环外先声明,那不同线程循环变量就会访问同一块内存,这样就会冲突。加入private(j)之后就会在每个线程生成一个副本,这样就正常了。
firstprivate
使用firstprivate(j)不仅有全局变量的副本,而且有他的值,在并行部分里对他进行修改不会影响全局变量的值。
捕捉私有变量
用数组的方式1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int main()
{
const int num = omp_get_max_threads();
int* aux = new int[num];
int i = 1;
{
const int j = omp_get_thread_num();
i += j;
aux[j] = i;
}
for (int i = 0; i < num; i++)
printf("aux[% d] = % d\n", i, aux[i]);
delete[] aux;
return 0;
}
运行结果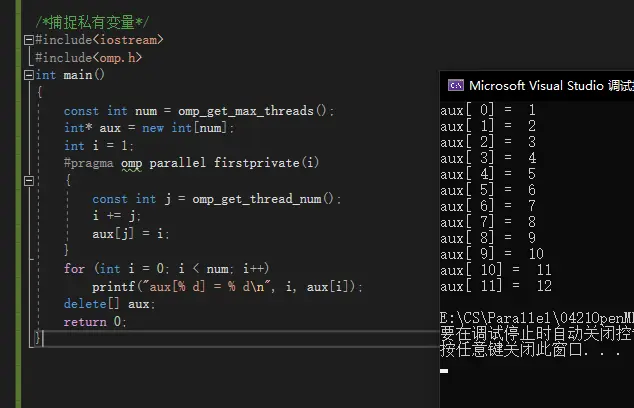
lastprivate
1 |
|
可以返回变量的值。
输出结果是3.
改为:1
2
3
for (int j = 0; j < 4; j++)
i = j + omp_get_thread_num();
输出结果是6.
DMV
1 |
|
运行结果:
自己电脑:
学校服务器: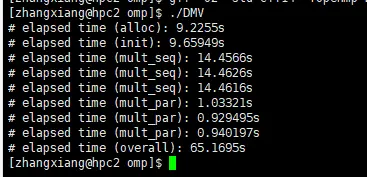
看来是x64不行。我改回了x86,然后量改成了13次方,结果是这样: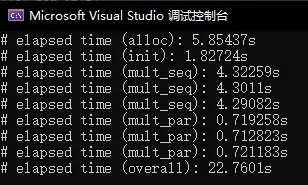
collapse
1 |
|
collapse折叠。因为这里钱两层循环紧挨着,所以可以“折叠起来”,超索引地给不同的线程分配任务。
有的时候,外层循环不多,但可用的线程非常你多的时候,可以用这种方法提高资源利用率。(解决负载不均衡。)
critical
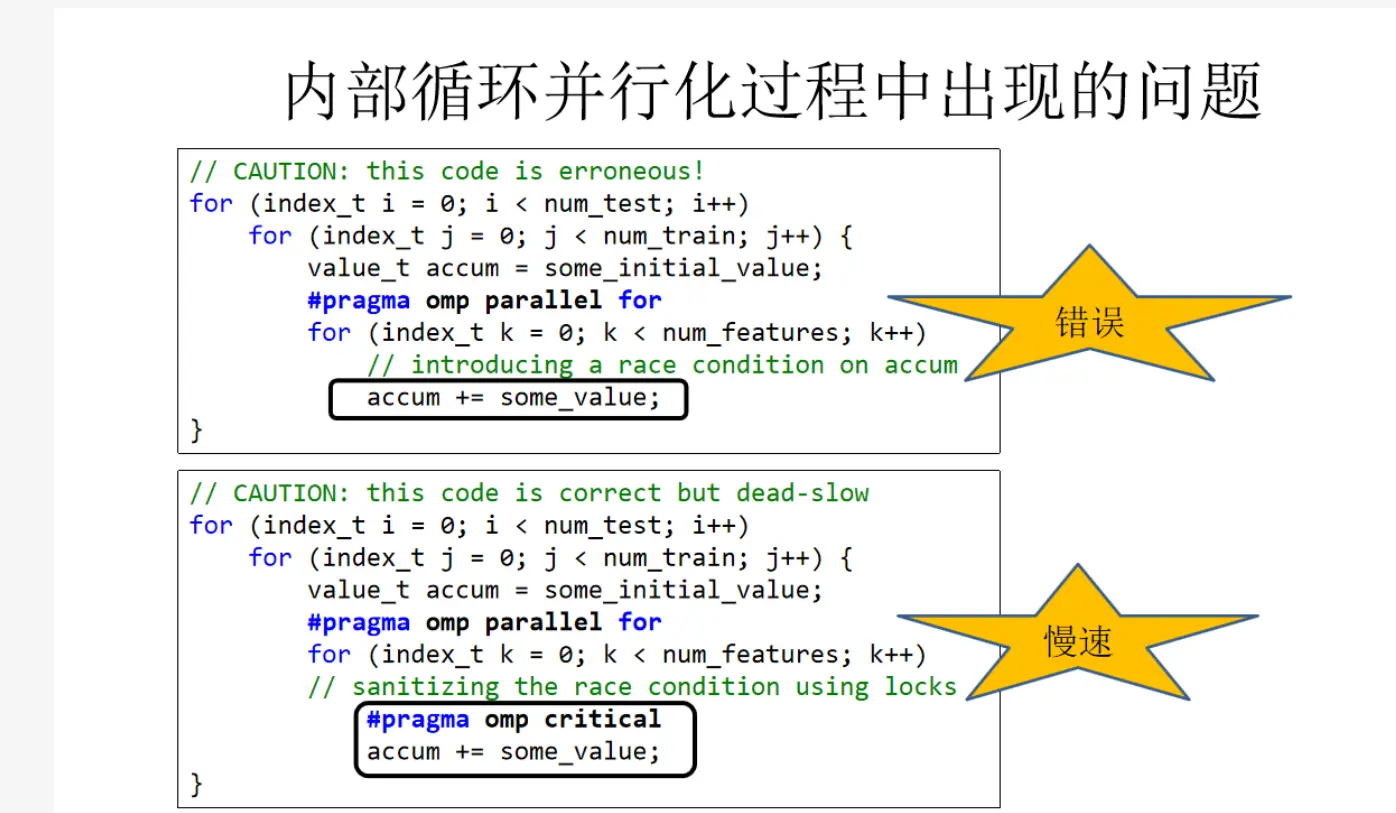
就相当于锁。
1NN(最近邻)
不平衡调度
是来研究parallel for怎么调度的。
格式:schedule(type[,size]),type可选有static , dynamic , guided ,runtime,size是个整数,前三种的时候,可写可不写,rumtime无需写很具环境变量来。
static
没有schedule,默认是static。1
2
3
4
5
6
7
8
9
int main()
{
for (int i = 0; i < 10; i++)
printf("i=%d,thread_id=%d\n", i, omp_get_thread_num());
return 0;
}
如果带了参数size,那它就会按线程编号0、1、2..的顺序,每个线程分配size个任务,一轮不够重头再来。如果不带参数,那它会让每个线程的数量均衡,比如10个循环4个线程的情况,4个县城依次是3、3、2、2。感觉它是算好怎样分配每个线程任务均衡,然后分配那么多连续的任务。
如果size为1,那就像之前的循环调度;不设参数有点类似于区块分发;参数大于1,就有点类似于块循环了。
dynamic
这种方式运行多次后给我的感觉是:
- 不带参数和参数为1效果一样;
- 带了参数之后,按任意编号顺序给每个线程分配
size多; - 如果一次之后还有没分配完的,那就都给0号线程。
- 但看mnist的运行结果和老师讲解,可能是谁闲下来谁上。
guided

runtime

auto
还有一种auto,由编译器和系统一起决定的。
归约
竞争条件。容易理解。不同的线程访问在并行区域外声明的变量并修改。
解决方案一:critical
前面有提到,就相当于锁。
解决方案二:归约reduction
x结果是4。
分析:
- 首先给每个线程分配任务,在这里因为没有schedule子句,所以按静态调度分,0号线程分前5个,1号线程分后五个;
- 每个线程声明一个私有化变量,叫中性变量,并赋予初值,因为这里是求最小值,所以赋值为无符号整型的最大值(64个1);
- 对中性变量做5次加1,得到4;
- 两个线程的结果和x的初始值取最小值返回给x。
reduction的基本操作: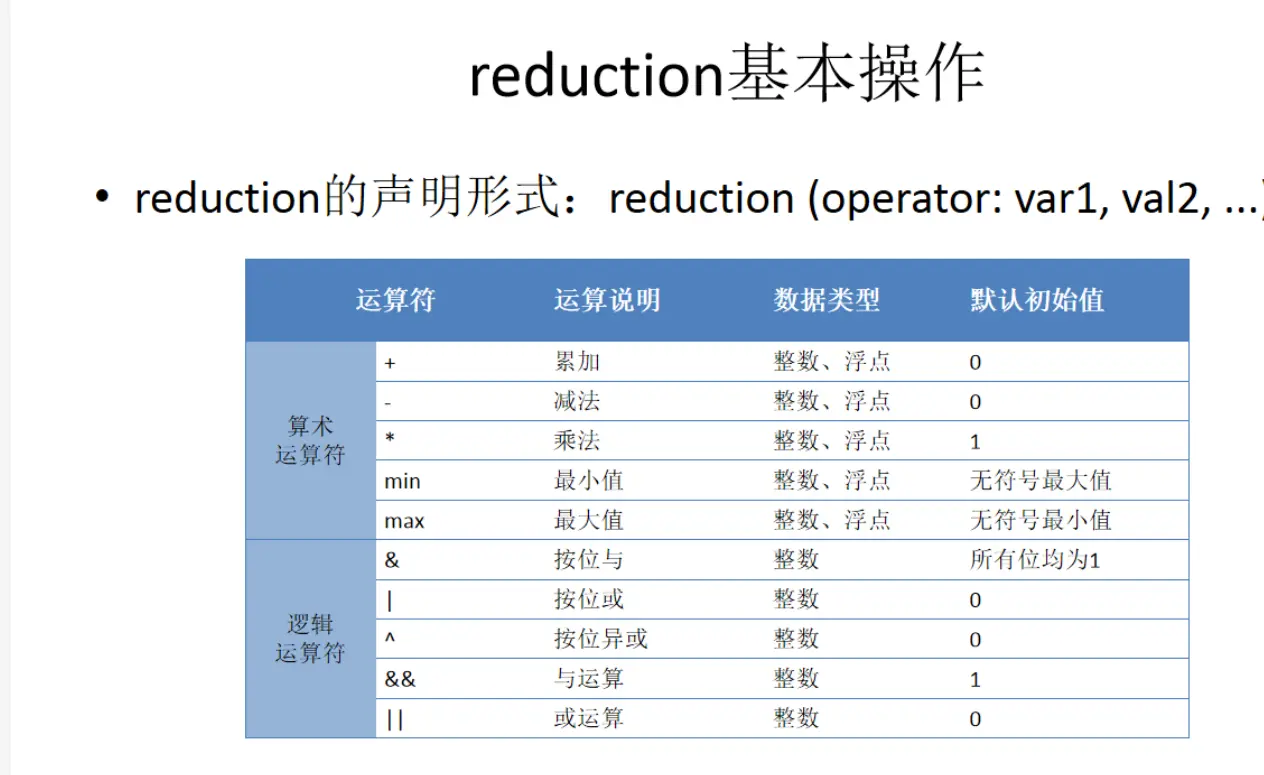
归约的数学性质或自定义归约的要求:

结合律、交换律、与中性元素运算后还是副本的值。(a,b,c是副本的值)
自定义归约
结构:1
2
3
(indentifier:typelist:combiner)
[initializer(initializer-expression)]
可以理解为:1
2
3
(自定义归约名字:类型:参数(或简单的表达式))
[初始化初值]
一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
//最大值返回函数
int mymax(int r, int n)
{
return r > n ? r : n;
}
int main()
{
const int num = 100;
int data[num];
for (int i = 0; i < num; i++)
data[i] = i;
int m = INT_MIN;
for (int i = 0; i < num; i++)
{
m = mymax(m, data[i]);
}
std::cout << "max=" << m << std::endl;
return 0;
}
结果是99
绝对值最大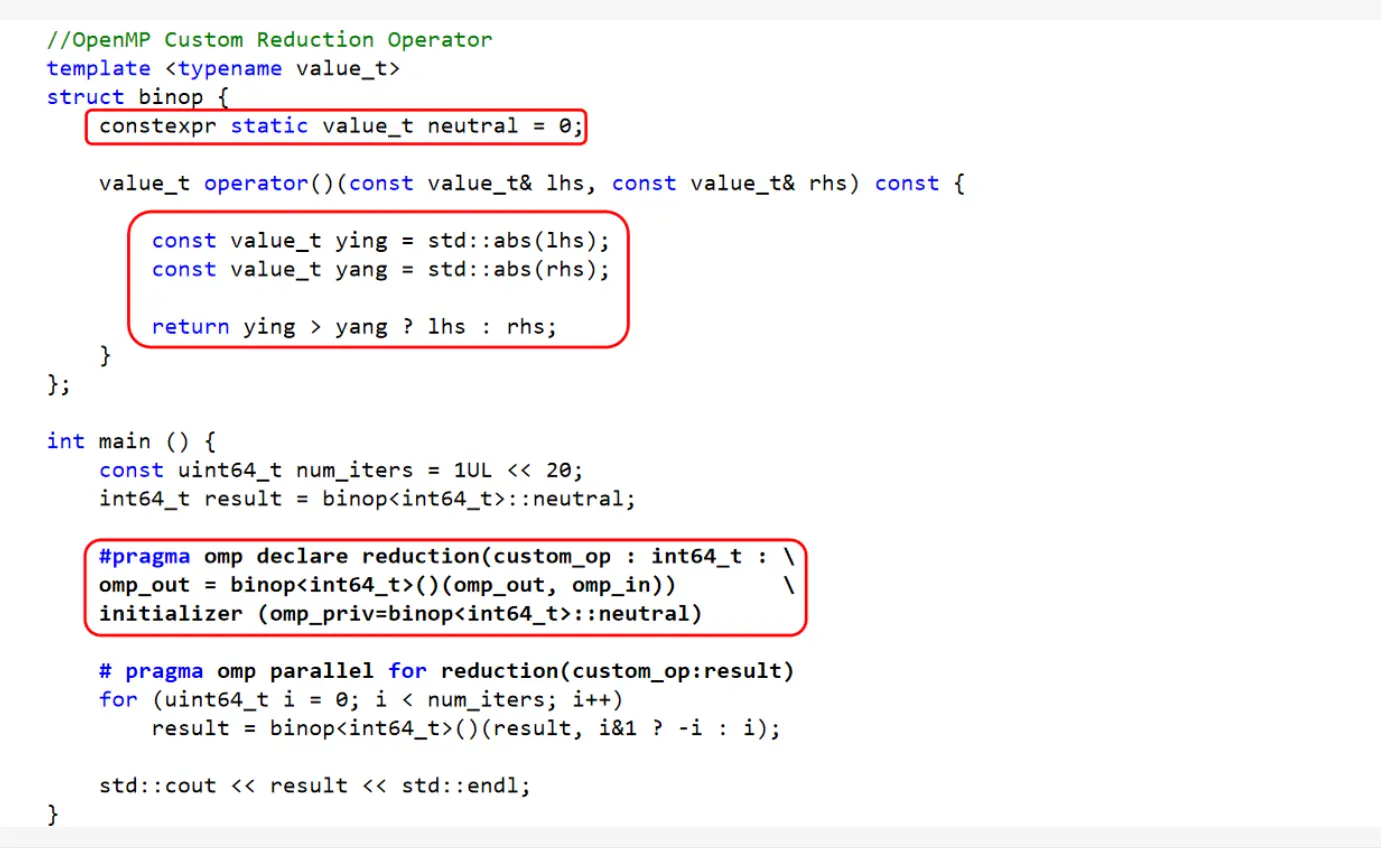
SIMD向量化
1 |

